

On this page
I’ve been pretty bullish on the future of AI models like Meta’s Llama 3 series and their inference stack. By making their platform widely accessible, Meta enables competitive innovation while pursuing platform and developer standardization - a natural fit for an industry moving toward small, customizable solutions. Yet, there remains a significant gap in the adoption of these models, leaving OpenAI to dominate with its industry-defining API standards on their own inference stack, which I believe fall into two key categories.
- Memory: Message inputs using a mix of text and/or images.
- Outputs: In the form of tool calling, ad-hoc JSON schemas, or alignment.
Messages are where memory management becomes crucial. Remember, AI models effectively have no memory - they only know the data they were trained on. Managing chat history is a chore no one wants to own, yet it's deceptively complex. This challenge, often paired with semantic retrieval, has fueled the rise of countless new databases. Unfortunately, many of these solutions fall short in usability and ease of ownership compared to OpenAI's Thread object, introduced in their long-awaited Assistant API. However, none of these tools adequately address the evolving adoption of graph-based RAG techniques, which offer more accurate and aligned retrieval capabilities.
Outputs are features that enable developers the most. Techniques such as function calling or capturing structured JSON as data typically reside outside of the AI model and are built into an inference company's API platform. I'll share a little how Zep can help with structured data, but our main focus today is around memory.
Zep's Open-Source Memory Layer
Personal AI has been a long running project I've been exploring. I have several AI experiments that require long form memory with the ability to continuous learn from Notion, synthesize knowledge, and maybe even one day execute tasks on my behalf.
Last month, I came across Zep's foundational memory layer and agreed to do this sponsored article, it turned out to be exactly what I needed for my projects. Beyond offering memory, it’s built on a temporal reasoning layer powered by knowledge graphs. Best of all, it’s entirely open-source under a project called Graphiti, which leverages Neo4j. I’ll dive deeper into knowledge graphs later.
Zep's memory layer is fully open and accessible, independent of any specific framework or AI platform. With Zep's Cloud platform, you can be up and running in seconds, no infrastructure required. On the integration side, I added Zep to my TypeScript project in just minutes using Vercel's AI SDK.
Today’s post will focus heavily on code as I walk through the key aspects of how Zep works. The examples provided are simplified and abstract, but if you’re looking for fully functional code, you can clone or reference the GitHub project linked below.
Zep builds a knowledge graph to create a comprehensive view of the user’s world, capturing entities and their relationships. Let’s start by focusing on adding "Relevant Memory" and "Chat Messages" (shown below) into our example project
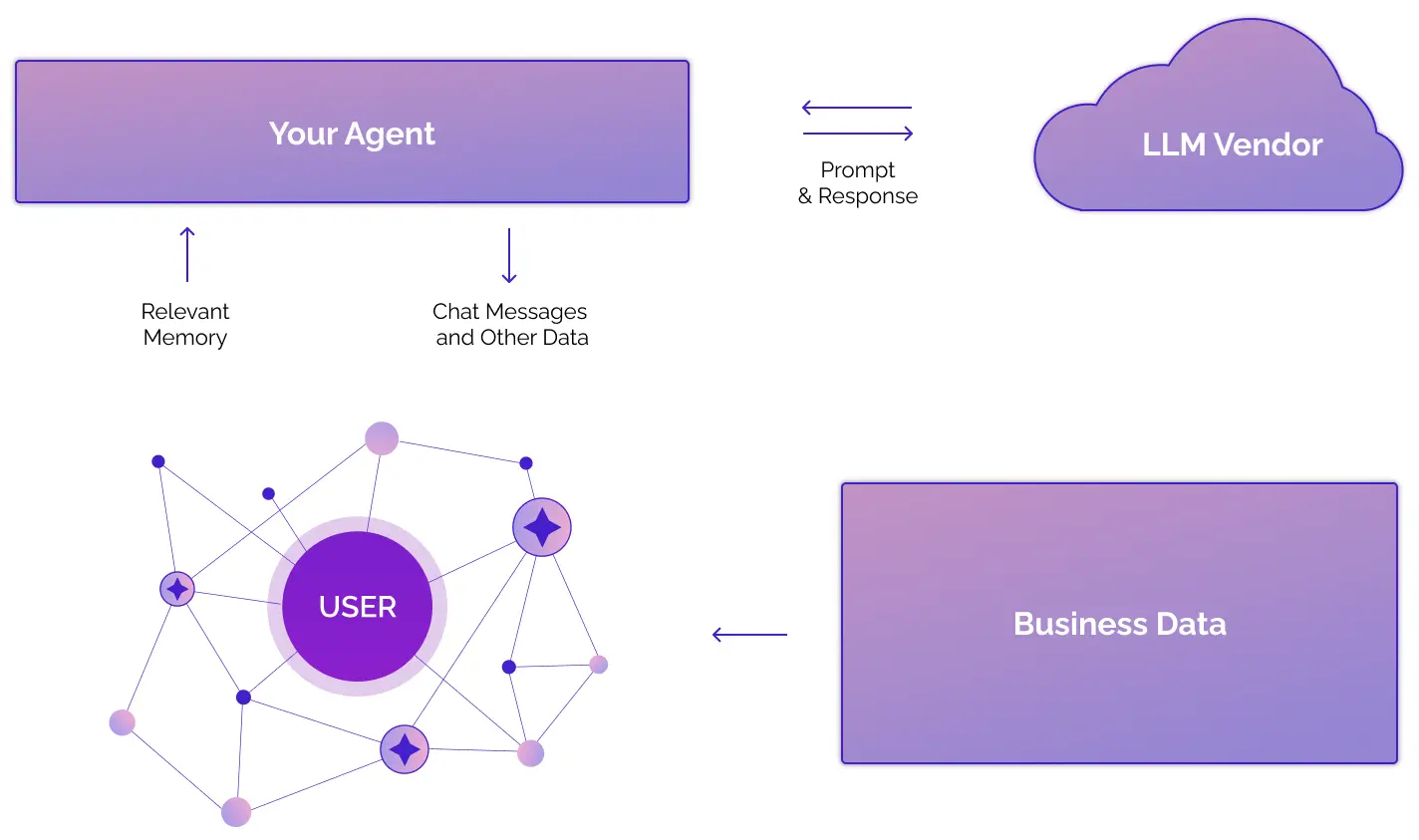
Relevant Memories & Chat Messages
To get started with Zep, the first step is to create a user and a session in Zep Cloud. For applications with anonymous users, you can easily generate random user IDs using any UUID library.
await zep.user.add({
userId: "1",
email: "ken@unremarkable.ai",
firstName: "Ken",
lastName: "Collins",
});
await zep.memory.addSession({
sessionId: "1",
userId: "1",
});Zep allows users to have multiple sessions contributing to the same shared memory. You can also connect multiple users as a group under one or even several sessions. Group-based sessions enable agents to access shared knowledge, such as documentation or group chats. Additionally, users with multiple sessions can maintain continuity in chats, even when logging out and back into an AI platform. It feels like Zep has all use cases covered.
Memory & Messages
Our GitHub project utilizes the streamText() interface from the Vercel AI SDK. Similar to most AI interfaces, it accepts an array of message history, including both the user's inputs and the assistant's responses. Below is a complete example demonstrating how to retrieve old messages and send them back to the model, now updated with a system prompt containing Zep's relevant memories. This approach is versatile and can be applied to any platform or framework!
// Next message from the User.
const newUserMessage = "Hi, my name is Ken.";
// Get all messages from the Zep memory API.
const memory: Memory = await zep.memory.get(sessionId);
const messages = memory.messages!.map((m: Message) => {
return { role: m.roleType, content: m.content };
});
// Send the new user message to zep and return an updated context
// string which contains facts & entities from the knowledge graph.
const { context } = await zep.memory.add(sessionId, {
messages: [{ roleType: "user", content: newUserMessage }],
returnContext: true,
});
// Send the old messages and new user message to your model with
// a system prompt that provides in-context knowledge for your agent.
const stream = streamText({
model: model,
system: `You are a helpful personal assistant. Use the following private facts and entities, which include timestamps, to inform your responses. Utilize the timestamps to ensure information is accurate and relevant, but do not mention or reference the facts, entities, or timestamps to the user in any way.
${context}
The current time is ${timestamp}.`.trim(),
messages: [
...messages,
{ role: "user", content: newUserMessage }
]
});The Zep Context
The context above describes how Zep manages memory when messages are sent to it. Zep dynamically creates relevant facts and entities using Graphiti's knowledge graph. Each message from the user or response from the assistant updates the graph, enriching the memory's context. The resulting context string looks something like this:
<FACTS>
- Ken is working on a Personal AI project. (2024-12-05 03:29:10 - present)
- user has the email of ken@unremarkable.ai (2024-12-05 03:28:40 - present)
- The user's name is Ken. (2024-12-05 03:28:40 - 2024-12-05 03:29:01)
- user has the id of 1 (2024-12-05 03:28:40 - present)
</FACTS>
<ENTITIES>
- Ken Collins: Ken Collins is working on a Personal AI project and is seeking ideas for use cases.
</ENTITIES>And just like that, any AI agent or chatbot can leverage Zep's memory capabilities. Their free plan is quite generous, providing access to all of Zep's features. I highly encourage you to sign up and give it a try today!
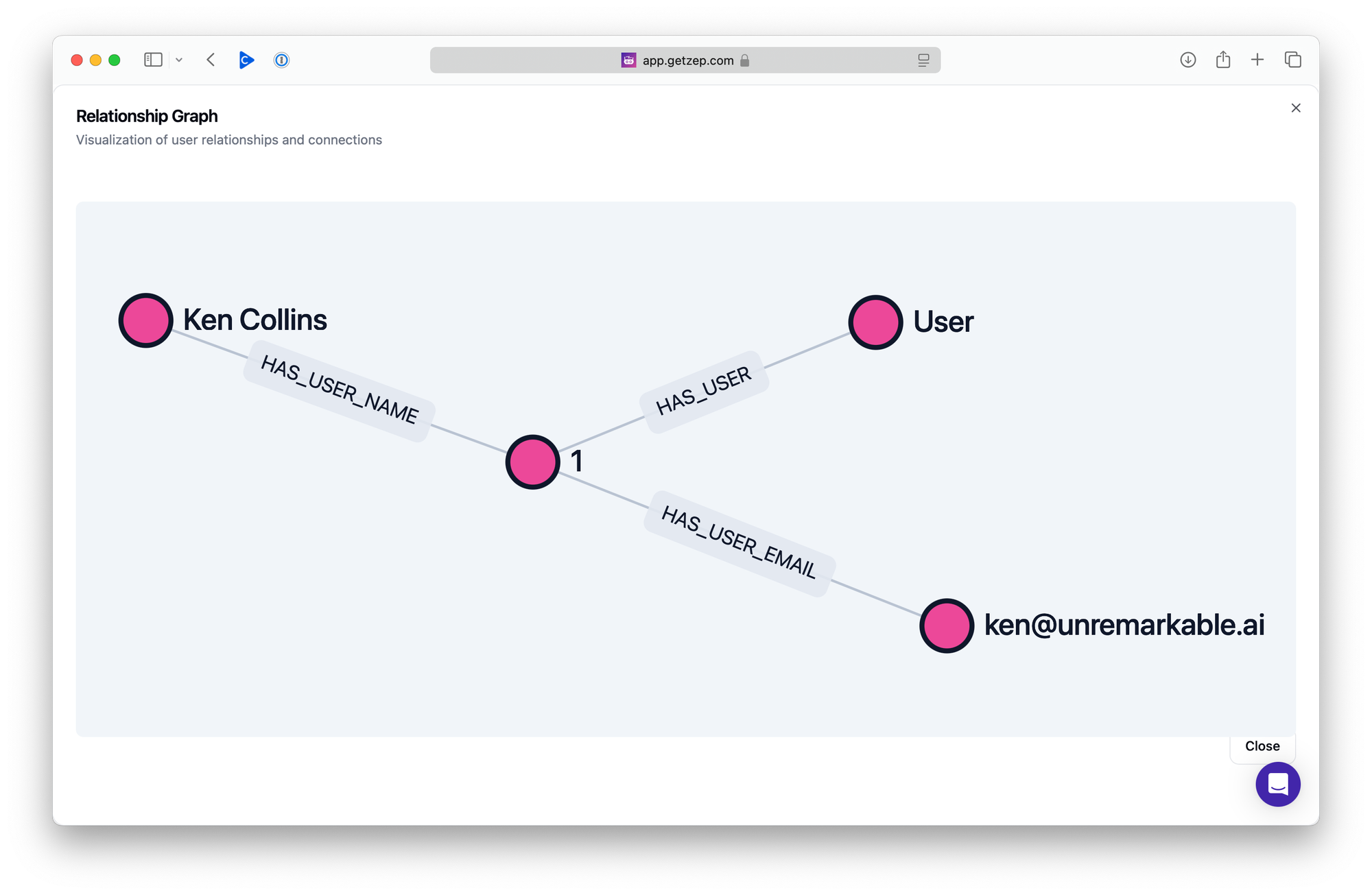
Exploring Zep's Knowledge Graph
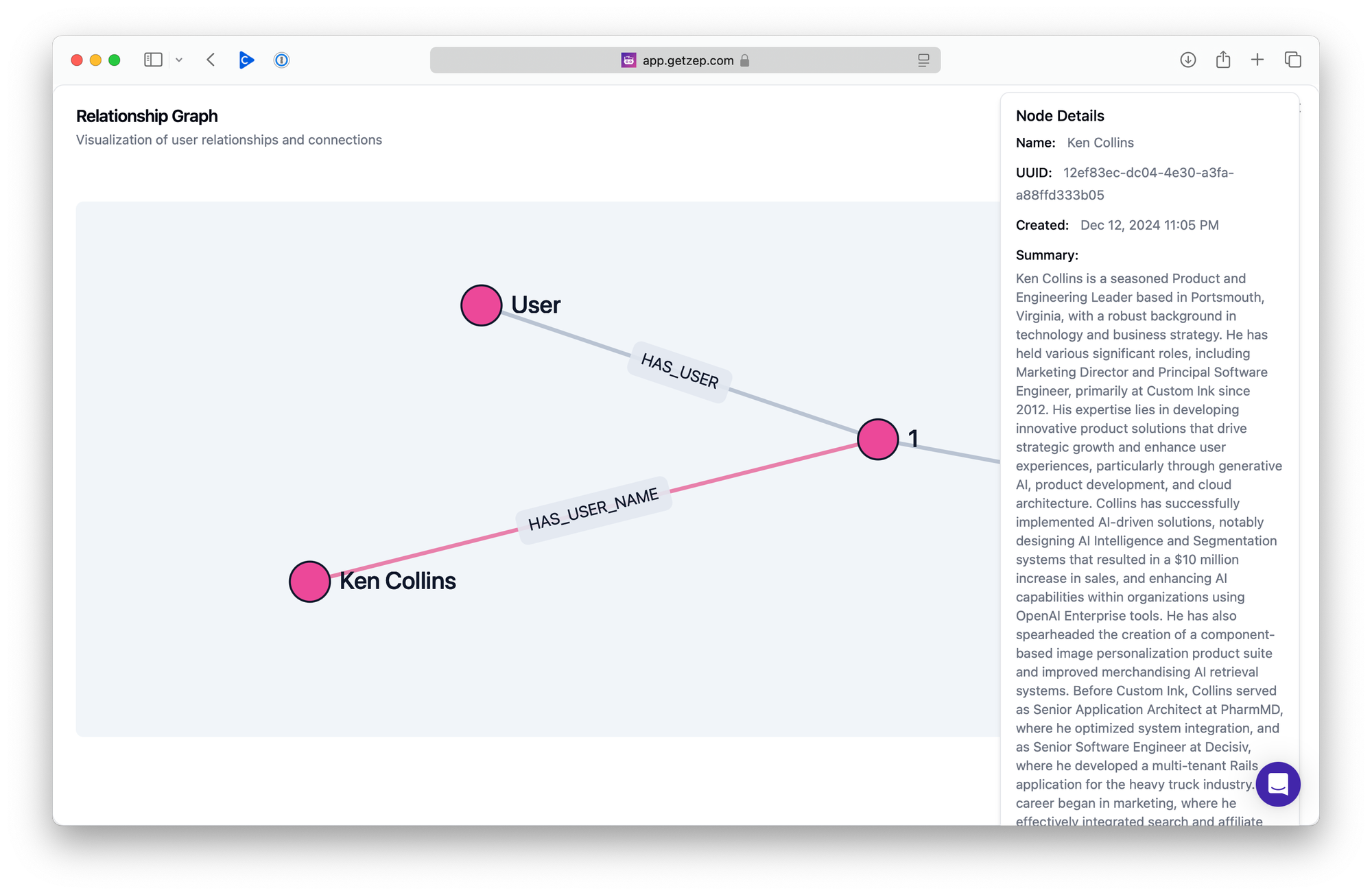
I'm eager to explore how to fully leverage Zep's knowledge graph. Zep offers APIs to add, read, and search the graph, making it highly flexible. From the Cloud console, you can inspect the graph for any user. For a basic user with no chat messages or additional data, the graph would look something like this:
Full Text Resume
How would this graph and the resulting memory context change when using something personal, like my resume? To find out, I converted my resume to Markdown using ChatGPT and tested it with the following code.
const myResume = await fs.readFile("ken.md", "utf-8");
await zep.graph.add({
userId: userId,
type: "text",
data: myResume,
});
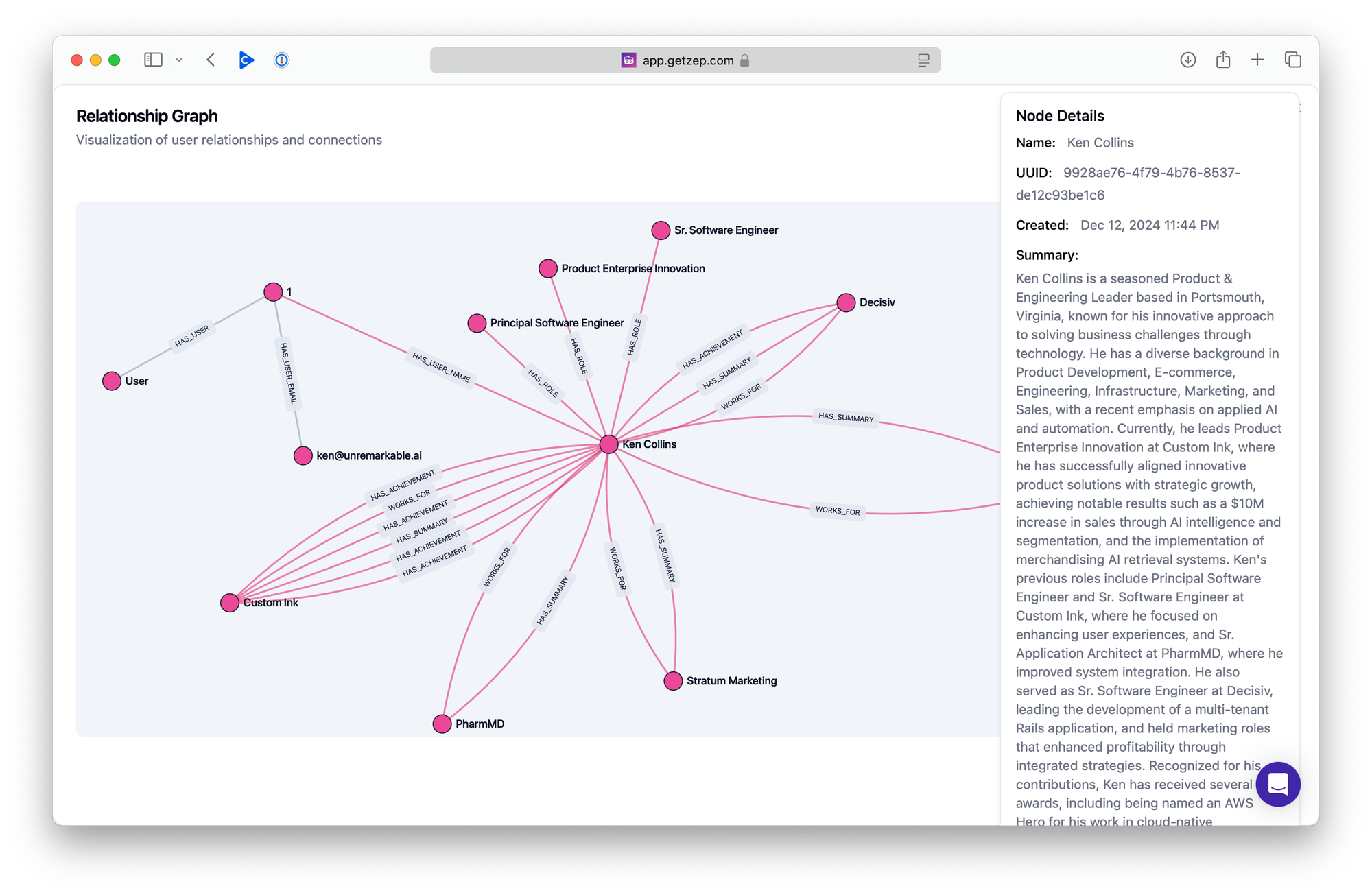
Structured JSON Resume
The results in chat were interesting, but I felt they could be improved. Looking at the graph (above), it was clear why: Zep had attached all the knowledge directly to my node. Depending on your use case, this might be ideal. However, I wanted to take a more deliberate approach to the results. To do this, I asked ChatGPT to convert my resume into JSON format and then added it to the graph.
const myResume = await fs.readFile("ken.json", "utf-8");
await zep.graph.add({
userId: userId,
type: "json",
data: myResume,
});
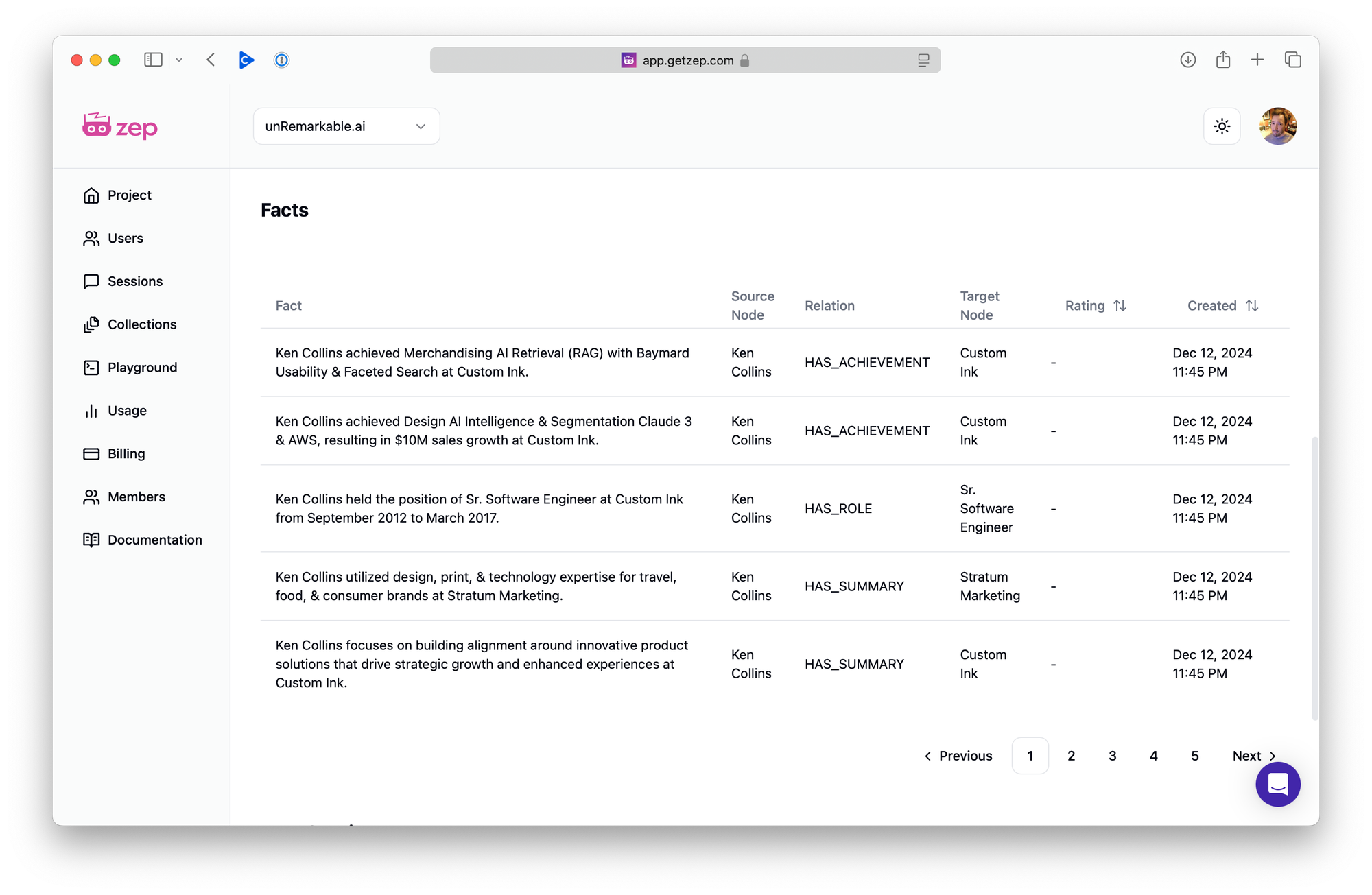
Now things are getting interesting. Along with a concise summary attached to my node, I now have a rich network of connections representing roles, achievements, and employers I have worked for. The resulting facts, which can also be viewed in the Zep Cloud interface, effectively tell the same story, providing a deeper and more structured representation of my experience.
Using Fact Rating Instructions
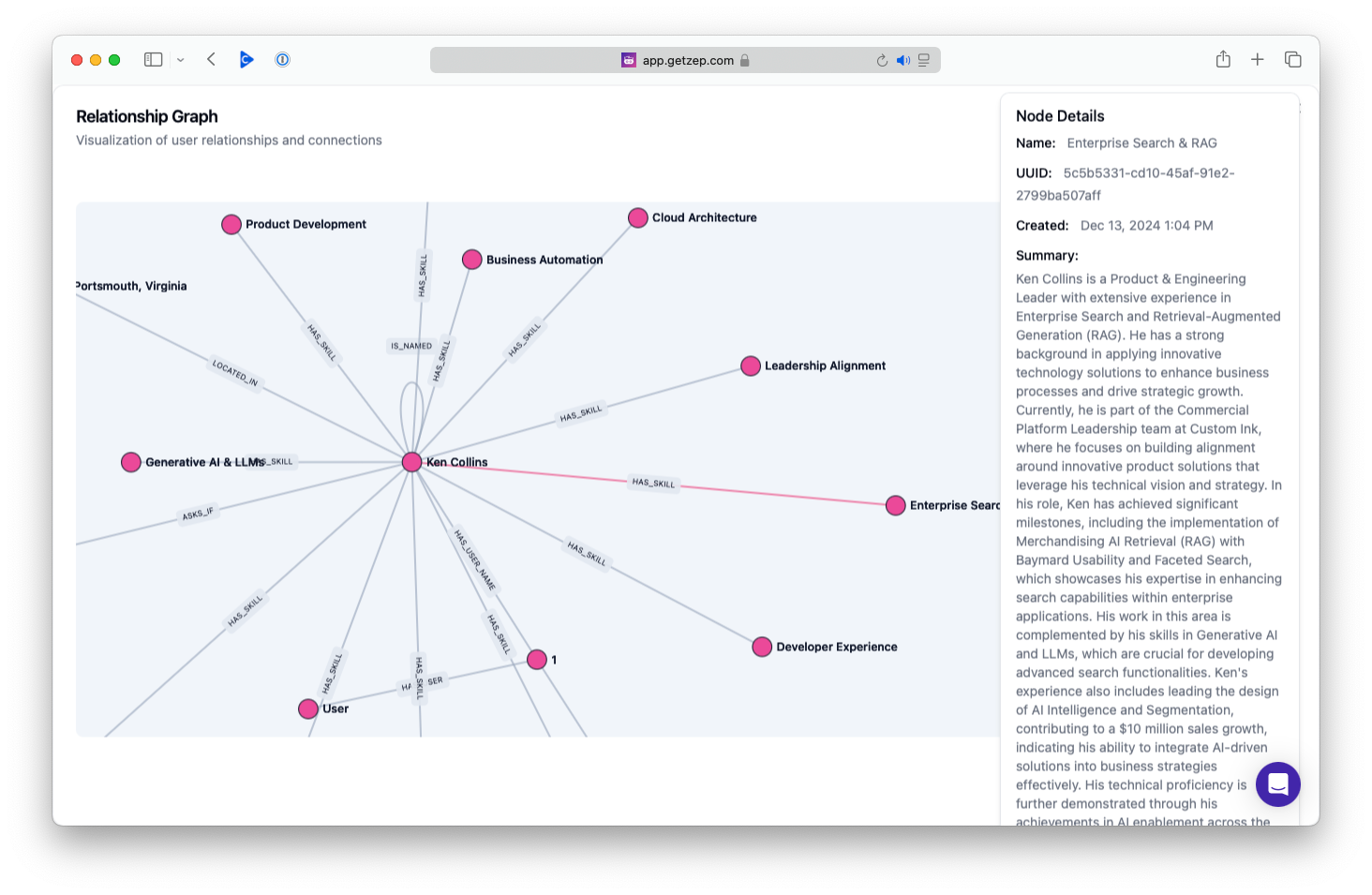
I wondered if I could intentionally influence how nodes are created and used by formatting my resume differently. That’s when I discovered, thanks to Discord, Zep’s fact rating instruction, which rates facts based on their relevance. The process is simple: you provide instructions along with a single example in your session. As new knowledge is added, Zep uses these instructions to generate facts. For instance, the instructions below are designed to build a skill tree from my resume.
factRatingInstruction: {
instruction: "Rate the facts by how well they demonstrate skills relevant to a specific job role/title at a particular point in someone's career history. Highly relevant facts show mastery of role-specific skills with clear context of when and how they were applied. Medium relevant facts indicate general capabilities related to the role but lack specific timing or application. Low relevant facts mention skills without clear connection to role or career timeline.",
examples: {
high: "As Principal Engineer at Custom Ink (2017-2020), the candidate led the mobile transformation of the Design Lab, resulting in a 35% increase in mobile saves and 20% rise in mobile orders through strategic leaadership and techncial responsive design innovation, setting the foundation for the company's future Design Lab platform",
medium: "While at Custom Ink, the candidate gained experience with AWS Lambda and Cloud Architecture skills.",
low: "The candidate knows CSS and HTML.",
}
}The results were fantastic! I hope these demos have inspired you to explore Zep for your current or upcoming projects. Feel free to reach out to me on Bluesky and let me know if you found this post helpful.
Shared Memory Is Strategic
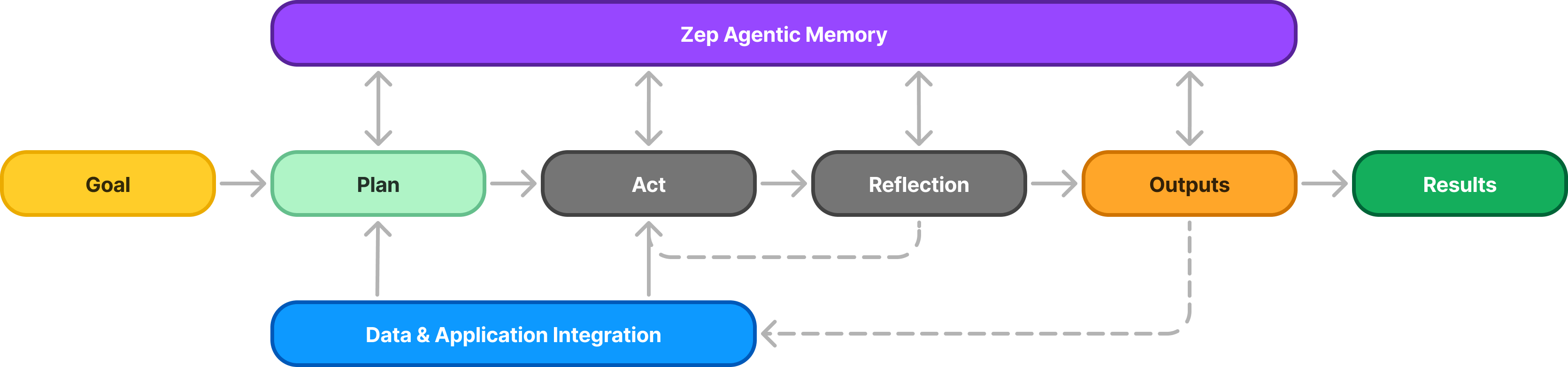
Breaking problems into discrete tasks is crucial for improving accuracy and alignment. This approach aligns with the Panel/Composition of Experts patterns, which I’ve discussed extensively in my Rise of the AI Copilots talk. For example, imagine each step - from "Plan" to "Outputs" - being handled by a different model optimized for that specific task. With Zep, memory can be seamlessly shared across these tasks, rather than simply passed, enabling a more decoupled and efficient workflow. My advice: take full advantage of this capability!
Other Closing Thoughts
🤗 Things are moving fast at Zep and new features are being added all the time. If you ever get the sense that something might be hard or difficult, join the Zep Discord server and ask for help, share your feature idea, or share more about your project's needs. They have a very active and welcoming community.
🧠 If you want to learn more about the open-source software Graphiti that powers Zep's cloud experience, take some time to read over their Knowledge Graph overview which breaks down in detail why knowledge graph driven context is so powerful for chat or any agentic workflow.
🤔 At some point I experienced Zep errors due to a single user message being over 2500 characters. I am not sure if this is a limitation of my free account, a bug with JavaScript SDK, or a limitation of the API itself. I found no mention of this in the documentation either.
🧱 Structured Data Extraction (SDE) is a challenging problem, and Zep's SDE from dialog messages is a promising step forward, positioning itself as a competitor to OpenAI's Structured Outputs. However, the available data types are quite basic, and in my testing, extracting knowledge requiring higher levels of reasoning proved difficult. Additionally, it lacks official JSON schema support and, as far as I can tell, a straightforward way to extract an array of objects within a defined schema.
🤝 One of the significant advantages of Zep's architecture is its support for shared sessions among a group of users. Additionally, a single user can maintain multiple sessions over an extended period, contributing to a richer, shared knowledge graph. However, it would be nice if Zep's sessions included an expiration date configuration for better lifecycle management. This flexibility is achievable with OpenAI's Thread object and something I think Zep could duplicate. This would allow for creating and destroying ad-hoc graphics at key points in your agentic workflows.
📖 The best way to get familiar with the API is by diving into the SDK's source code. For instance, I found the resource clients in the TypeScript source particularly helpful—especially the Memory client. Exploring this code provides valuable insights into how the API works and how to effectively use it.
What's Next?
If you’ve been following our Chat History for Llama 3 with Zep demo project on GitHub, you may have noticed some lightning-fast AI inference happening behind the scenes. Stay tuned—I'll dive deeper into that in next week's post!




