

On this page
OpenAI o1 is approximately 30 times slower than GPT-4o. Similarly, the o1 mini version is around 16 times slower than GPT-4o mini.
Frontier models are getting slower! Yup, you heard that right. A few days ago Google released Gemini 2.0 Flash Thinking with experimental reasoning to compete with OpenAI's thinking model, o1. The day after, on December 20th, OpenAI came right back with their o3 announcement (no release yet) with AGI-like performance that stunned our community. In that video Greg Kamradt, President of the ARC Prize Foundation, showcased some impressive benchmarks for o3. But you might be stunned to learn at what cost.

Aside, I got to meet Greg at OpenAI's DevDay event in San Francisco a few months ago. The ARC Prize has become a crucial benchmark for me as an applied AI practitioner, since the tests are straightforward for humans but typically trip up AI models using the transformer architecture.
While Greg shared some fascinating data on o3's reasoning capabilities, I think Riley Goodside's graph (left) really drives home that we've entered a new era.
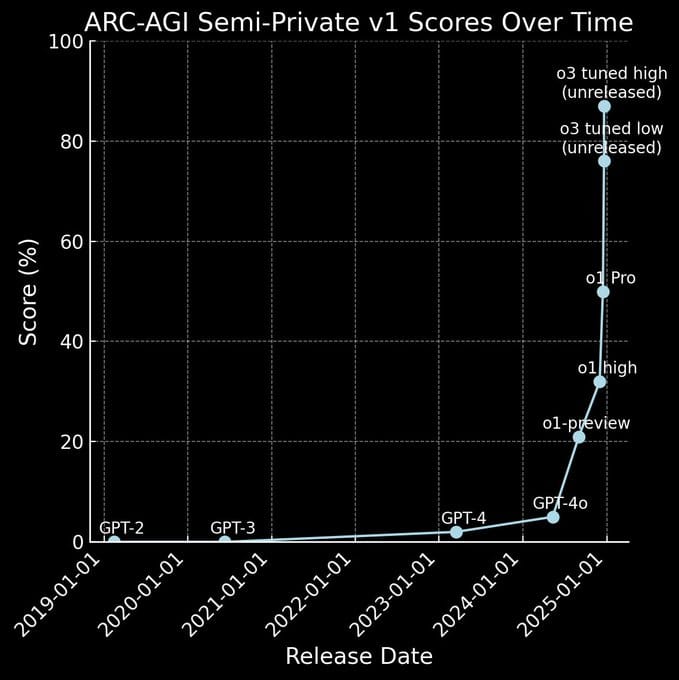
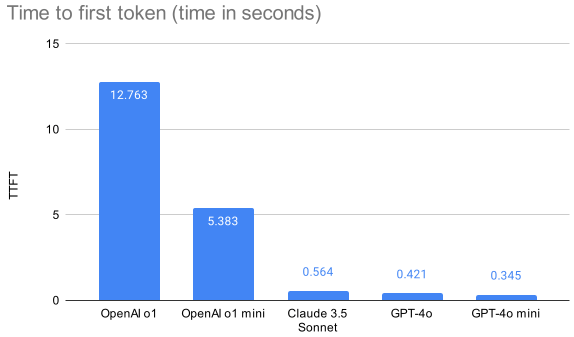
The secret behind o1 and o3's huge gains in the ARC AGI evaluation? It's called "test-time compute" - basically letting the model take its time to "think." While o1 can crank out about 150 Tokens Per Second (TPS), there's a catch: its reasoning abilities come with a longer Time to First Token (TTFT), which means you're waiting longer overall. You can see this trade-off in the graph above (right) from Vellum's comparison of OpenAI o1, GPT-4o, and Claude 3.5 Sonnet. OpenAI's o1 model is approximately 30 times slower than GPT-4o. Similarly, the o1 mini version is around 16 times slower than GPT-4o mini.
What is Test-Time Compute?
Think of test-time compute like giving AI more time to mull things over (and burn through more token$) instead of just feeding it more training data. It's similar to other prompting techniques like Planning, ReAct, Chain of Thought, Reflection, or Mixture of Experts. There are two main ways it works:
- Multiple Attempts: Just like a student might solve a problem different ways and pick their best solution, the AI can generate several answers and use a rewards system to choose the most promising one.
- Step-by-step Checking: Picture a student breaking down a tough problem into smaller chunks and double-checking each step - the AI does something similar by evaluating its reasoning as it goes along.
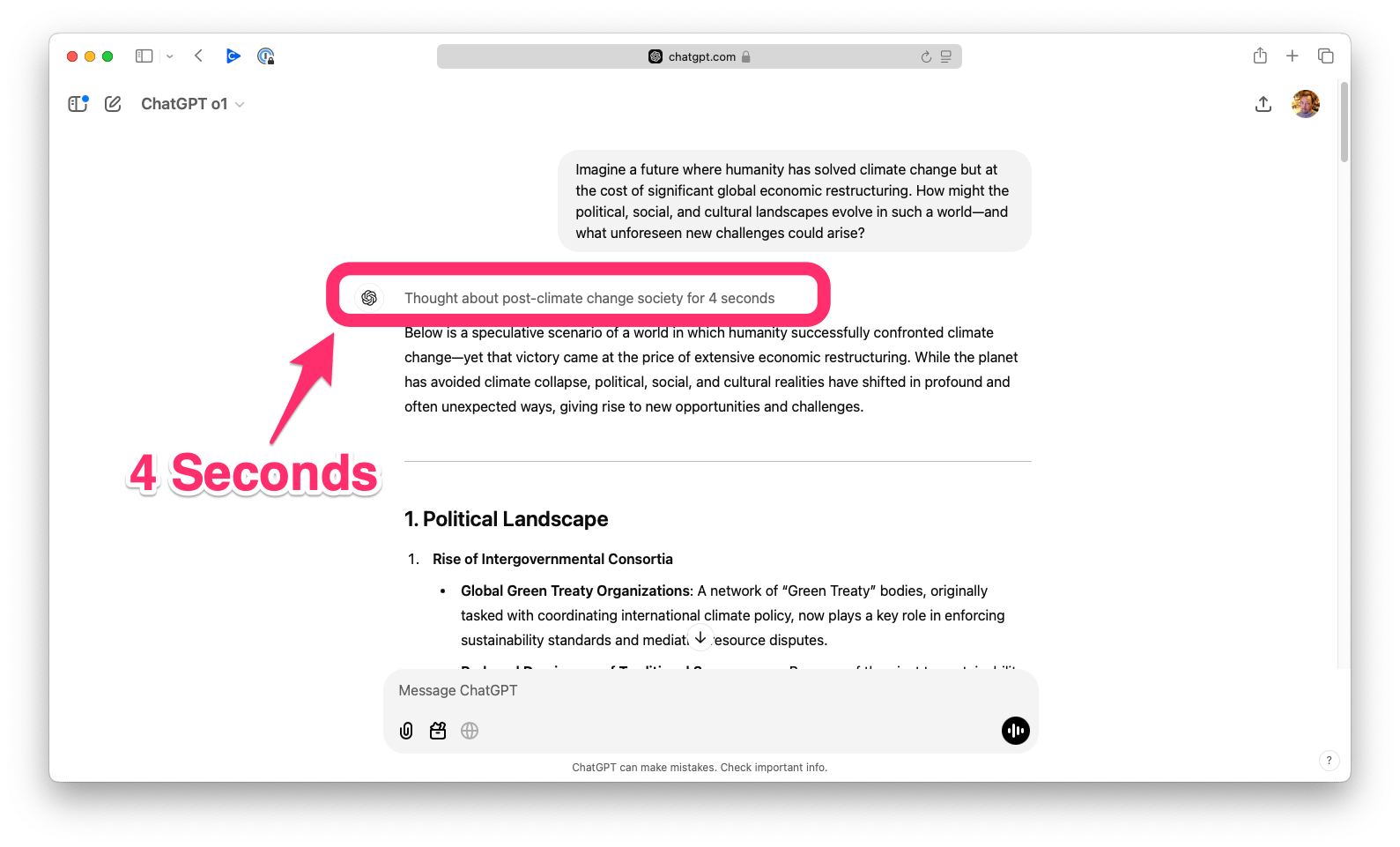
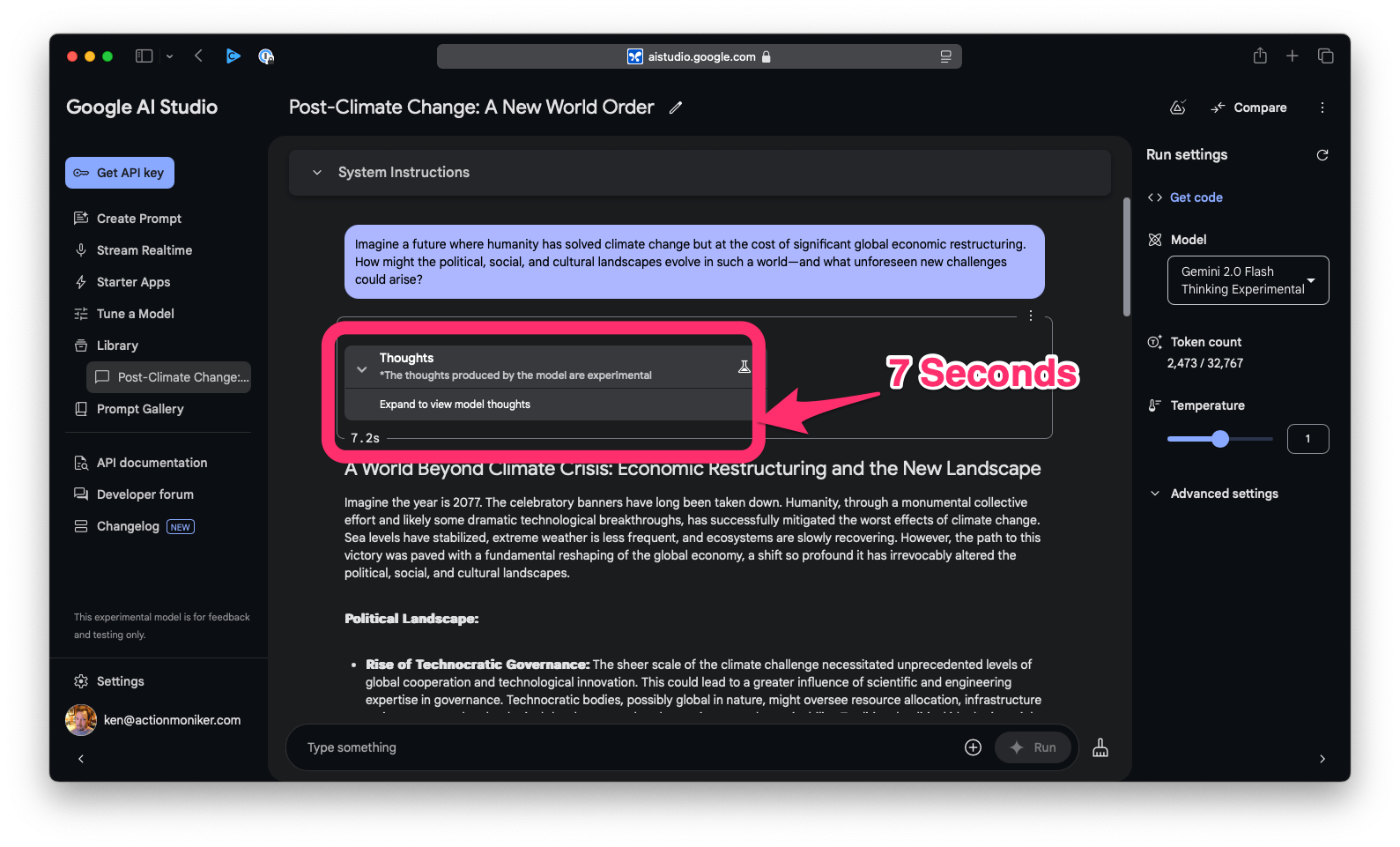
You can see test-time compute in action when you use ChatGPT or AI Studio. There's no fixed rule for how long a model might think or why. I tested both models with the "ultimate question" about life, the universe, and everything 😜 - both came back pretty quickly with an answer. So I used this prompt instead:
> Imagine a future where humanity has solved climate change but at the cost of significant global economic restructuring. How might the political, social, and cultural landscapes evolve in such a world-and what unforeseen new challenges could arise?
- 4 Seconds - OpenAI o1
- 7 Seconds - Google Gemini 2.0 Flash
Few seconds isn't too bad. But what about the o3 model? The amount of test-time compute it used for the ARC AGI benchmarks? Matthew Berman breaks this down in his The World Reacts to OpenAI's Unveiling of o3 video and the numbers are absolutely mind-blowing 🤯.
- The semi‐private ARC AGI run included roughly 172 tasks.
- The o3 model spent about 16 hours total on test run.
- Inference cost was around $2,000 per task, adding up to $350,000 total.
- This comes out to roughly 5-6 minutes of thinking time per task.
So it looks like test-time compute is the future of AI... but right now it's both expensive and slow - the question is, for how long? Should we all switch our agentic systems to these reasoning powerhouses and bet on faster compute coming soon? My advice? Don't do it. I'm still feeling burned after investing so much time into Experts only to find OpenAI's Assistants API with multiple agents crawling along at a snail's pace one year later.
We Need Fast Decisioning
So the push for higher AI accuracy is shifting our scaling laws from training to inference time - costing us more $$$ while slowing things down. The later is more important when you consider human-in-the-loop interactions. In some cases, a legal must. Consider that Jakob Nielsen laid out three critical response time thresholds for Human Computer Interfaces (HCI) back in his 1993 book Usability Engineering which I think are more important than ever now at this decisioning junction.
- 0.1 Second - Instant: The sweet spot. Users feel they're directly manipulating objects in the interface.
- 1 Second - Flow Maintenance: The limit for keeping user thought flow uninterrupted. Users lose that feeling of direct manipulation.
- 10 Seconds - Attention Limit: Users start looking for other things to do while waiting. Their performance takes a hit.
Looking at these numbers, we're clearly headed in the wrong direction. I'm tired of sitting through SaaS chatbot demos where I'm waiting 30 seconds to 2 minutes while some multi-agent system digs through knowledge and tries to align it. I worry people will start carelessly throwing thinking models at everything without considering how they're killing the human efficiency gains we've all worked so hard to achieve for these systems' users.
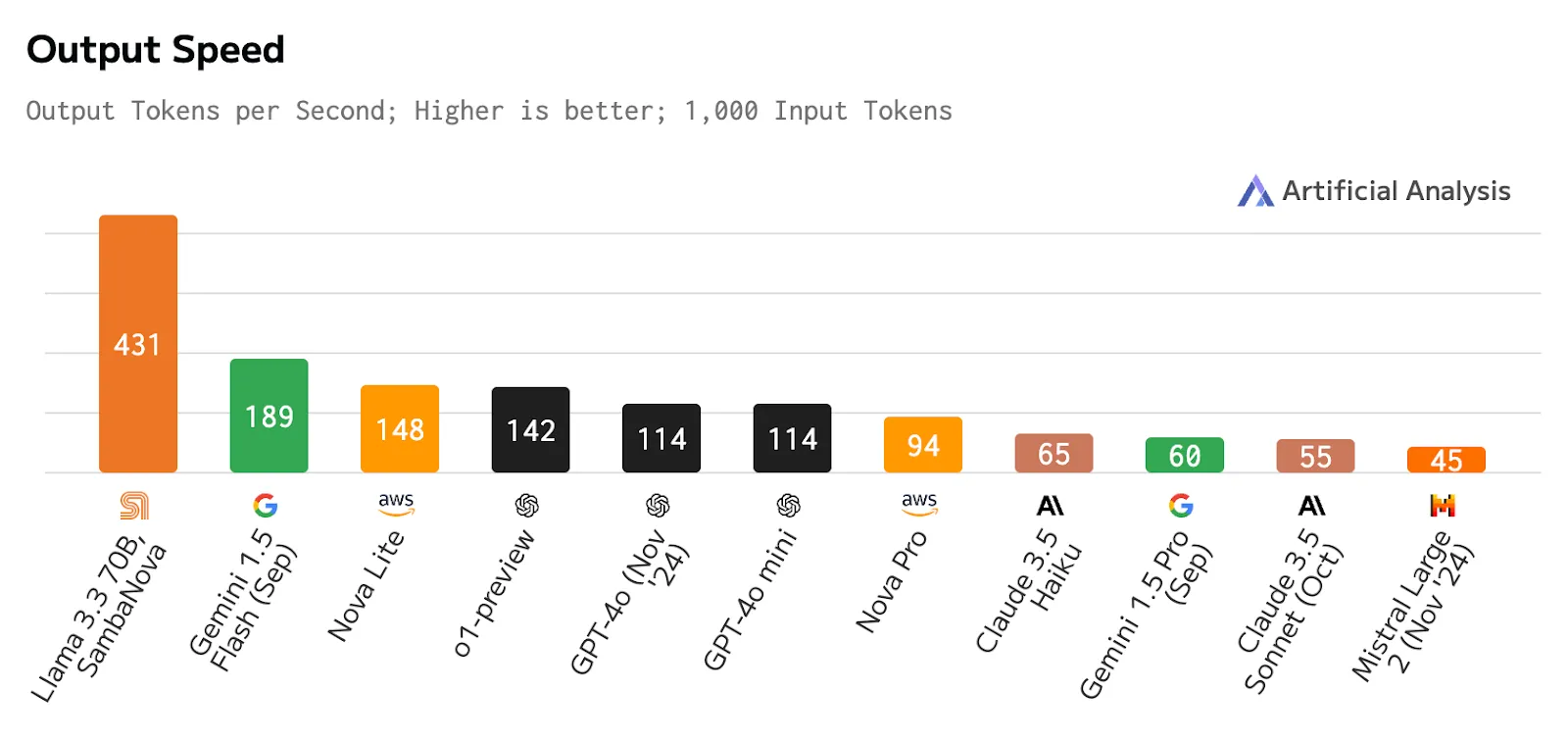
Don't get me wrong - these reasoning models are crucial tools in our applied AI toolkit. I think there are opportunities in the next year to nail the basics first. To push open-source models (sans thinking) to their limits. The good news? Companies like SambaNova are shaking up the scaling laws and unlocking new possibilities!
Compound AI Systems
In recent news, multi-agent systems have rebranded themselves as "Compound AI" systems, with Lin Qiao, CEO of Fireworks AI, making the case in a recent article that:
The future of AI lies not in monolithic models but in dynamic workflows where multiple specialized models and tools work together to solve complex tasks.
Yup! This isn't exactly new territory - in my Rise of the AI Copilots talk, I discussed a AI pipeline at Custom Ink that at one time leveraged four different models in a bounded context. It is rather easy to do with basic SDKs and easy to optimize as new models are introduced. Generally lowering costs as well. Compound AI does work!

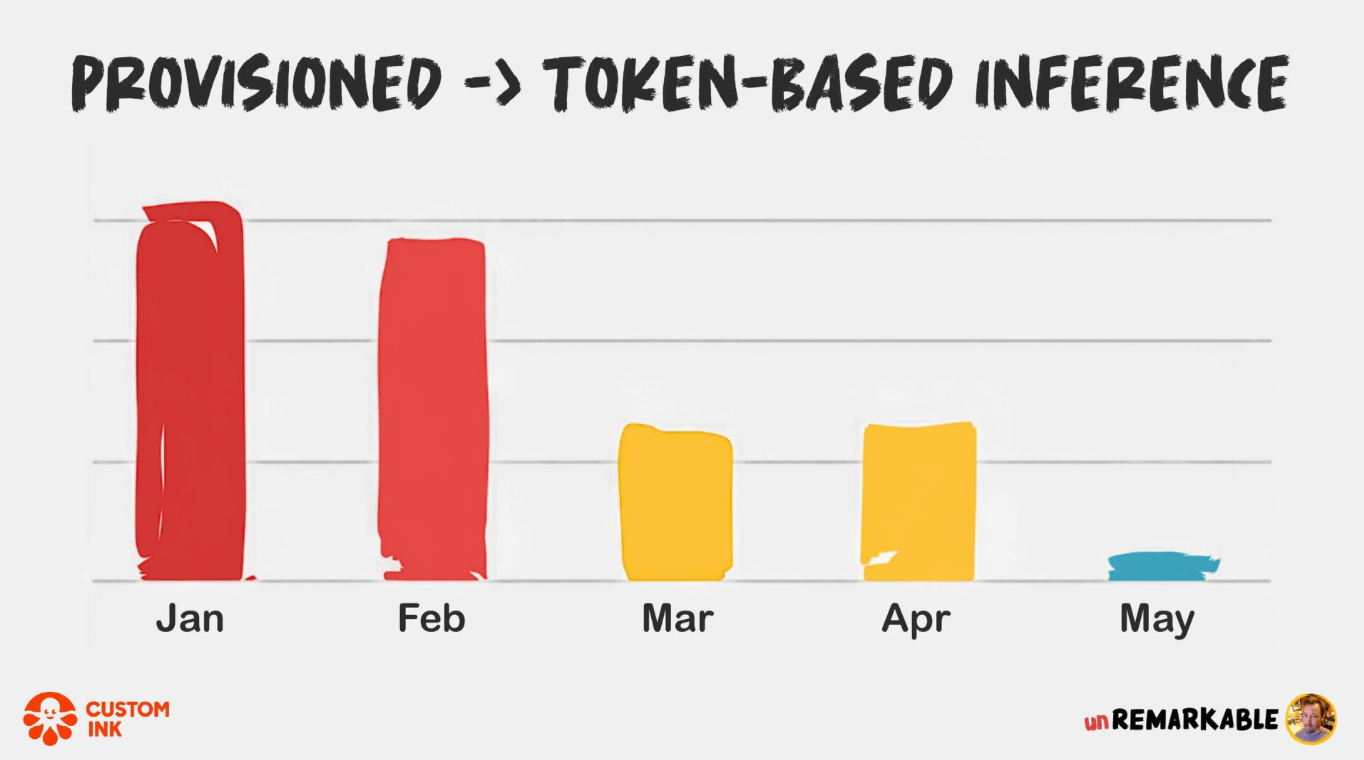
Last week I shared how new memory layers are a key part of these newly branded Compound AI systems. It's worth a read.
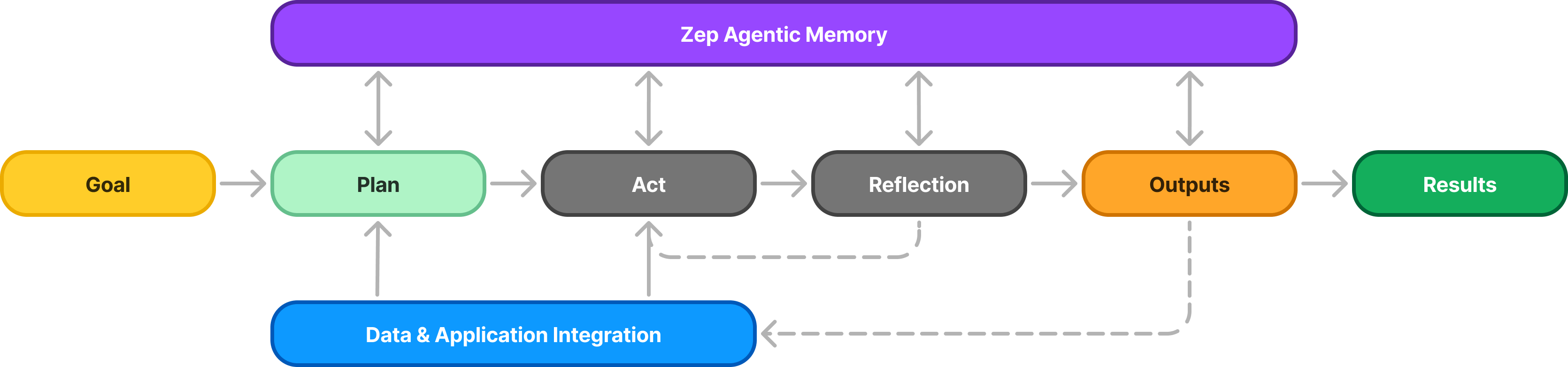
In related news, Stanford Professor Christopher Potts reinforces this view in his recent talk, emphasizing that while frontier models get the media attention, the real innovation is happening in compound systems that combine different AI components for practical business applications. With the emergence of powerful orchestration tools and frameworks, we're now better equipped than ever to build these sophisticated multi-model systems that can deliver real business value without the prohibitive costs and latency of frontier models. Let's explore how SambaNova can help here!
Building with SambaNova
SambaNova Systems has launched a groundbreaking AI inference service called SambaNova Cloud that delivers world-record speeds for running Meta's Llama models, including the recently released Llama 3.3 70B.

So all we need now is a use case - something that needs an AI agent to break apart a complex problem into smaller decisions that we can implement with Llama, with strict evaluations and performance measurements. While learning about Exa's semantic AI search the other night, I found their open source Hallucinations Detector project on GitHub. Perfect, we're going to duplicate this project with SambaNova. The code is below if you want to follow along.
Creating a Claim
I thought it would be fun to see how Exa's search would validate (or not) a basic Perplexity search. So I asked it, "When did Amazon Bedrock come out with cross-region inference?" and then ran that claim through Exa's tool.
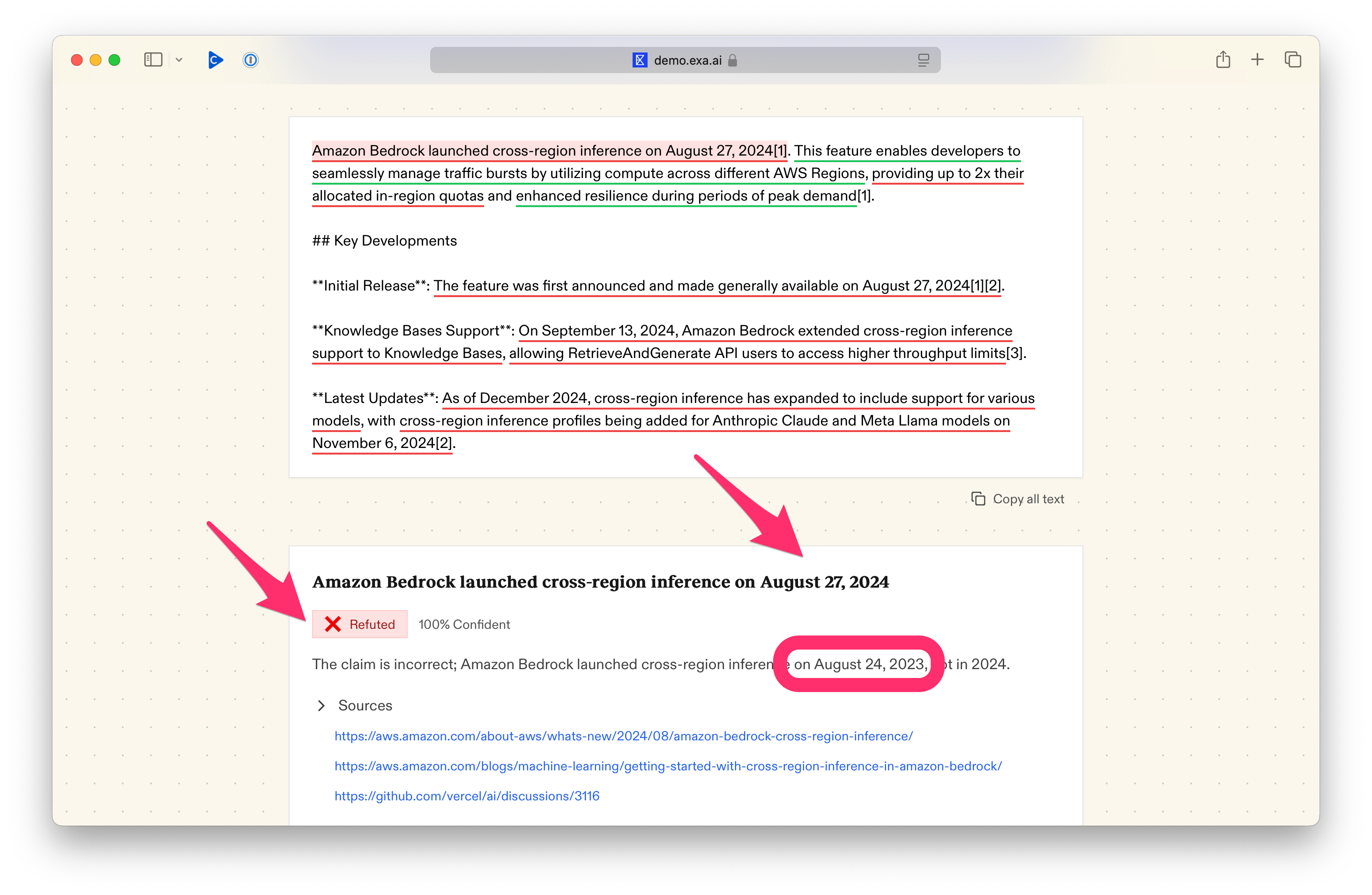
The results? Perplexity was right, but Exa's tool wasn't able to validate it. In fact, the hallucination detector itself hallucinated, probably because it couldn't find the same sources. So our project now has:
- A Bedrock search claim from Perplexity in markdown.
- Three Perplexity sources saved as markdown. (made with Firecrawl)
Why save the source crawls in the repo? I wanted my evaluations to measure only the LLM calls. So I felt having these as static resources would give us better measurements.
Building our AI Agents
Again, I'm going to use the Vercel AI SDK for this project. Since SambaNova has an OpenAI-compatible API, the client is really easy to set up. The project has two agents:
- Extract Claims - Parses the top 3 claims from a piece of content in JSON format.
- Verify Claim - Given a single claim, verify that claim against all the sources looking for inconsistencies or nuanced factual information.
Both of these agents will use the Llama 3.3 70B model.
const sambanova = createOpenAI({
name: "sambanova",
apiKey: process.env.SAMBANOVA_API_KEY,
baseURL: "https://api.sambanova.ai/v1",
})("Meta-Llama-3.3-70B-Instruct");We coordinate those agents in a single script which extracts all claims and output the results using the npm run demo command. You should see something like this:
✅ Amazon Bedrock launched cross-region inference on August 27, 2024
Summary: The claim is correct as Amazon Bedrock did launch cross-region inference on August 27, 2024, as stated in the provided sources.
✅ Cross-region inference provides up to 2x the allocated in-region quotas
Summary: The claim is correct as cross-region inference provides up to 2x the allocated in-region quotas according to the sources.
✅ Cross-region inference support was extended to Knowledge Bases on September 13, 2024
Summary: The claim is correct as cross-region inference support was indeed extended to Knowledge Bases on September 13, 2024, as stated in the provided sources.If you change the first claim's date to the 25th and run it again, we can see the agents working to detect the fake hallucination. Hooray! 🎉
❌ Amazon Bedrock launched cross-region inference on August 25, 2024
Summary: The claim is incorrect because Amazon Bedrock launched cross-region inference on August 27, 2024, not August 25, 2024.
Fixed Claim: Amazon Bedrock launched cross-region inference on August 27, 2024Evaluations
So how much faster is SambaNova than other inference platforms? We could time those command but I thought it would be fun to use Braintrust's platform which make it really easy because it can leverage Vercel's support for OpenTelemetry. Braintrust comes with dozen's of evals including JSON output following a schema. Perfect for dealing with some open-source model's lack of support for Structured Outputs.
I tested the Verify Claims eval against Amazon Bedrock running the same model. The results are outstanding. SambaNova is nearly 4x faster!
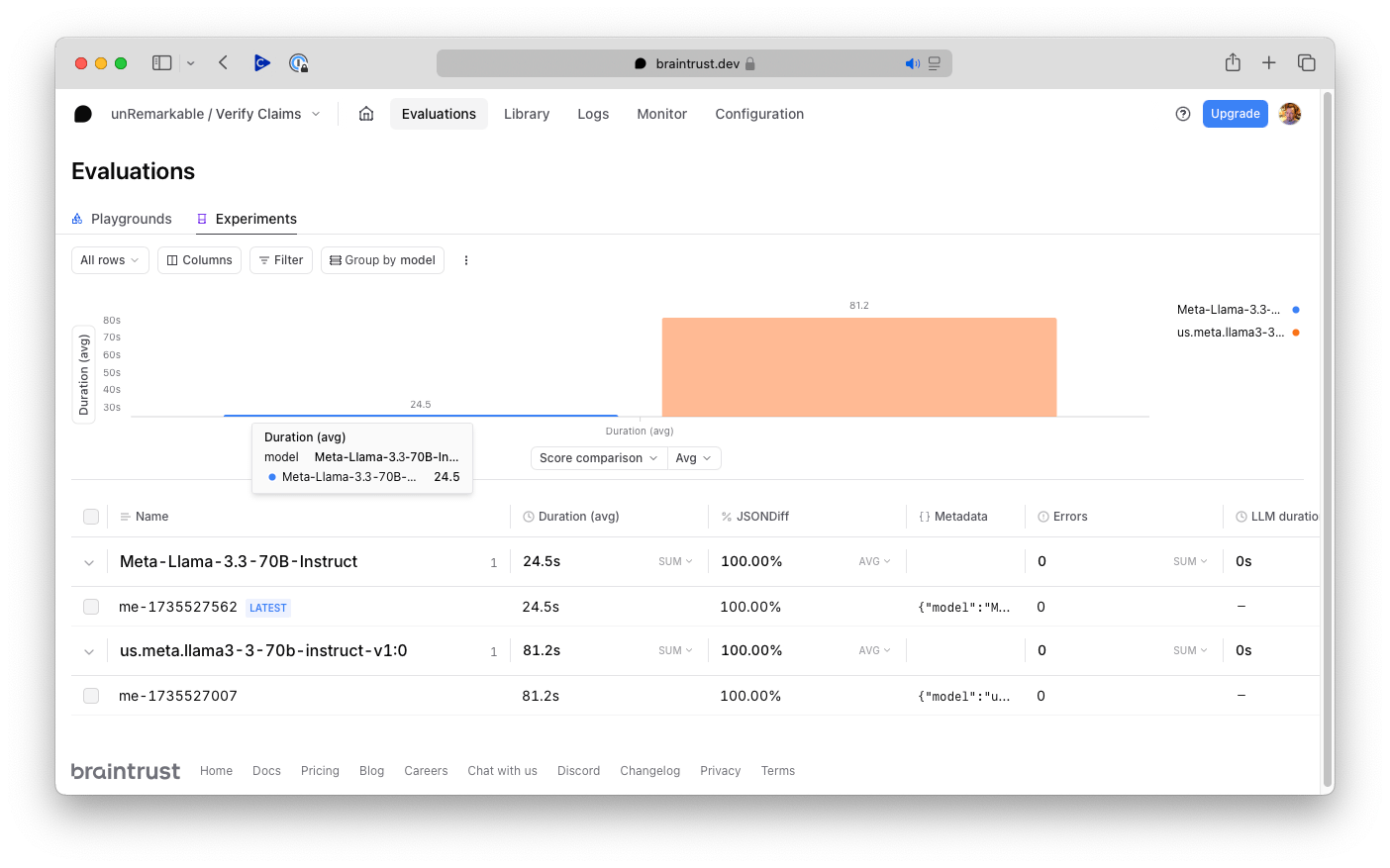
So in this example we have moved from ~81 seconds on Amazon Bedroc to ~24 seconds on SambaNova. My next experiments are going to be using smaller Llama models on SambaNova for hyper fast Compound AI solutions that run in less than a few seconds. I hope you enjoyed this article and encourage you to start thinking of use cases that were previously unthinkable due to inference speed on other platforms.

Have fun kicking the test-time compute trend which could slow down your agentic systems.


