

On this page
Knowledge Navigator
If you have interacted at all this year with OpenAI's 💬 ChatGPT you may think we are closer than ever to 🎥 Apple's 1987 Knowledge Navigator. A way to interact with a computer that most of us have only seen in SciFi movies. At first glance today, these language model's knowledge do feel eerily expansive and unlimited. With very little context they can solve interesting problems in highly probabilistic ways.


Yet for knowledge workers, these models are still very limited in their ability to help us. We have all seen the "As of my last update..." or "I don't have real-time..." messages when asking about current events or within a highly specific domain. It is frustrating to hit these roadblocks for those looking to use data, often proprietary, with our friendly Large Language Models (LLMs). After all, half of the video above is an AI resembling Mark Zuckerberg in a bow tie responding to new data. But how?
Retrieval-Augmented Generation (RAG)
Did you know that "GPT" in ChatGPT stands for ℹ️ Generative Pre-Trained Transformers? The key words here are "generative" and "pre-trained". It is easy from these terms to understand that ChatGPT is pre-trained on massive amounts of knowledge and it generates real language responses based on that knowledge.
A GPT model can learn new knowledge in one of two ways. The first is via model weights on a training set (fine-tuning). The other is via model inputs or inserting knowledge into a context window (retrieval). While fine-tuning may seem like a straightforward method for teaching GPT, it is typically not recommended for factual recall, but rather for 💩 specialized tasks. OpenAI has a great cookbook titled 📚 Question answering using embeddings-based search where they make these points on your choices.
| Fine-Tuning | Retrieval |
|---|---|
| As an analogy, model weights are like long-term memory. When you fine-tune a model, it's like studying for an exam a week away. When the exam arrives, the model may forget details, or misremember facts it never read. | In contrast, message inputs are like short-term memory. When you insert knowledge into a message, it's like taking an exam with open notes. With notes in hand, the model is more likely to arrive at correct answers. |
Open book exam? I'm sold. After all, this is how the internet works today. Information is retrieved over many different protocols, locations, and APIs. If you would like to keep exploring this topic I have included some references below on how on retrieval-augmented generation fits into the current market and the opportunities and tools available today.


Meta: Retrieval Augmented Generation

IBM: What is retrieval-augmented generation?
YouTube: Retrieval-Augmented Generation (RAG)
Basic Architecture
Our RAG's architecture with OpenAI is going to follow this diagram. Our demo application described in the next article of this series will only focus on using OpenAI's Function Calling feature since we are building a stand-alone chat application. If you were building ChatGPT Plugin, that is when you would use the OpenAPI Definition.
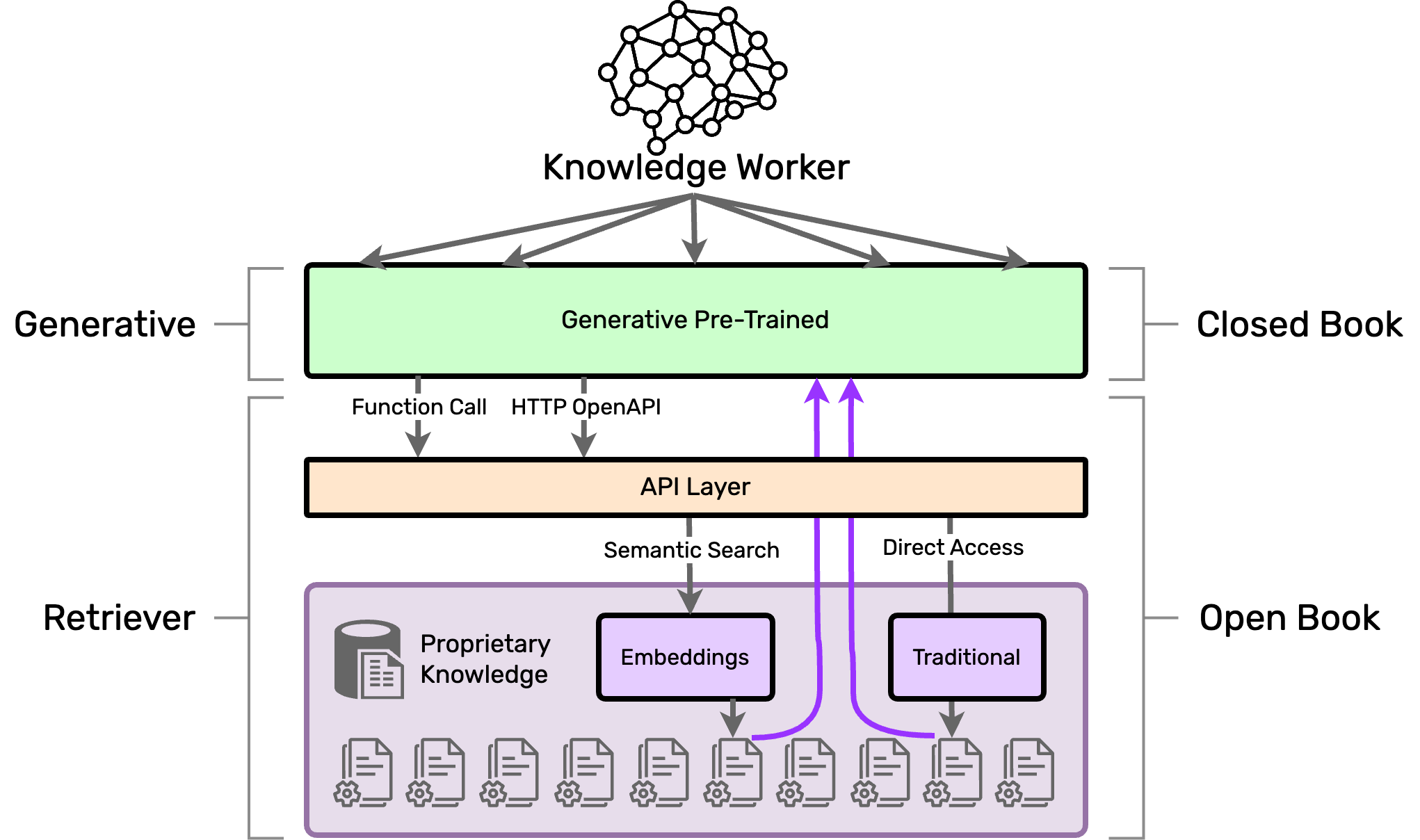
Our demo will also showcase using SQLite for Semantic Search as a fast and easy to use vector database that can store and query our Vector Embeddings. Vector embeddings are numerical representations of complex data like words or images, simplifying high-dimensional data into a lower-dimensional space for easier processing and analysis.
Lastly we are going to need some proprietary data to use with our RAG. I chose the Luxury Apparel Dataset from Kaggle. It contains ~5,000 products with good descriptions and categories to facet.
Context Windows
So how much data can we insert into a message when retrieving data? The answer depends on the size of the model's Context Window. This refers to the maximum number of tokens the model can consider as input for generating outputs. There is a growing trend and demand for LLMs with larger context windows. For instance, some previous generation models could only consider 2,000 token inputs, while some more advanced versions can handle up to 32,000 tokens.

So is the context window our Moore's Law for LLMs? Some think so. There is even thinking that we get diminishing returns with larger models. While newer Claude models are pushing 100K tokens, some think Less is More and solid retrieval patterns are the key to good results. We should all keep an eye out as we rapidly explore this area of AI.
